
PDF-Scanner-Pro for Android
- REQUIRES ANDROID | Published by Jian Yu on 2024-11-07 | Category: Business
Rating 0
from 0 Votes |
$ Free
- REQUIRES ANDROID | Published by Jian Yu on 2024-11-07 | Category: Business
 |
 |
 |
 |
APK (Android Package Kit) files are the raw files of an Android app. Learn how to install pdf-scanner-pro.apk file on your phone in 4 Simple Steps:
Yes. We provide some of the safest Apk download mirrors for getting the PDF-Scanner-Pro apk.
Won’t even open on Android 2016 13-inch Retina with OSx 10.13.3 (the latest as of 3/9/2018.) I re-downloaed and re-installed. Still won’t work. I will report it to Google and ask for a refund.
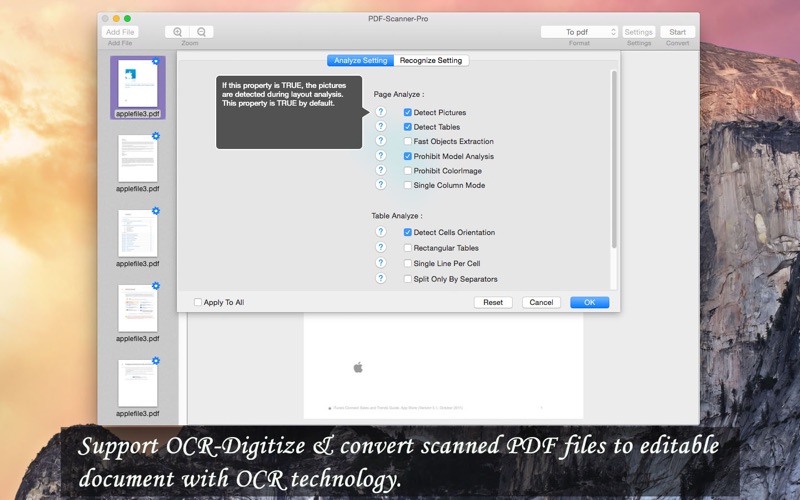
This app needs to be re-titled or re-catagorized!!! The app DOES NOT scan from a printer/scanner.
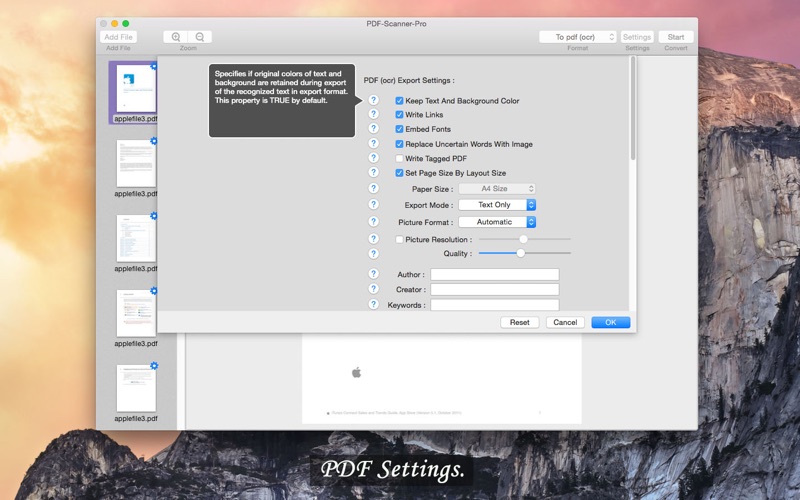
The description claims it does "advanced OCR" but it does not. I tried the free version converting a TIFF image file which contained only clear English text. The program copied the TIFF and created a PDF which contained -- an image file identical to the input. There is NO TEXT in the PDF only the copied image. It did NOT do OCR (character recognition) of the text in the TIFF, it just duplicated the TIFF as a single image. That is not OCR -- the output PDF cannot be searched, and words in the text cannot be selected. I have not tested it with a PDF (my only interest was capturing text from images saved by the grab.app utility). However I strongly suspect that if a PDF contains an image of text, for example a page made from a scanner, it will not capture the text from that image either. In short it does not actually do OCR at all.
This is just what I needed for scanning a lot of documents to PDF. Full of features, but very easy to use. You can use tokens to create file names based on date, etc. Scanning is fast and accurate. The developer answers questions quickly and thoroughly. Can’t ask for much more in an app.
This app does one thing exceptionally well - scans PDF document to PDF, And it makes the process so simple.

|
|

|

|

|

|

|

|

|

|



