Text Extractor for Android
- REQUIRES ANDROID | Published by 科 姚 on 2013-08-30 | Category: Business
Rating 0
from 0 Votes |
$ $9.99
- REQUIRES ANDROID | Published by 科 姚 on 2013-08-30 | Category: Business
 |
 |
 |
 |
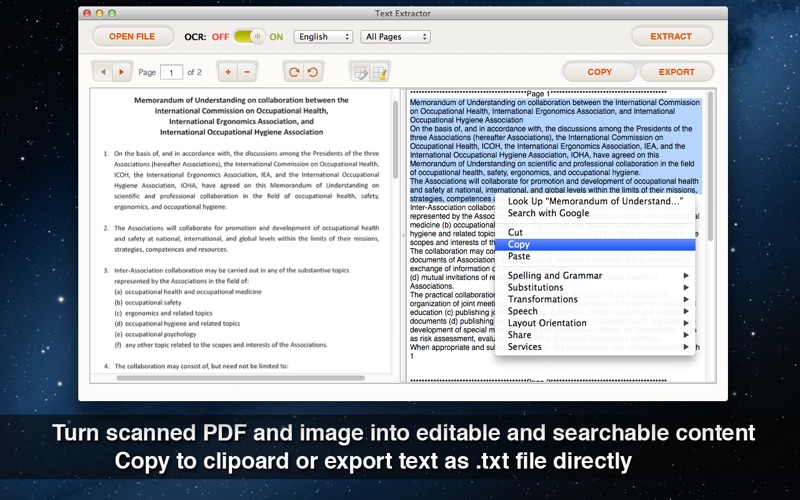
APK (Android Package Kit) files are the raw files of an Android app. Learn how to install text-extractor-extract-text-from-pdf-image-with-ocr.apk file on your phone in 4 Simple Steps:
Yes. We provide some of the safest Apk download mirrors for getting the Text Extractor apk.
For the documents I’ve been working with, this app has not been able to generate anything but gibberish at all. This cost too much money for its limited functionality, and should not claim the effectiveness that it does. Not worth the money and a waste of time.
It does not work most of the time.
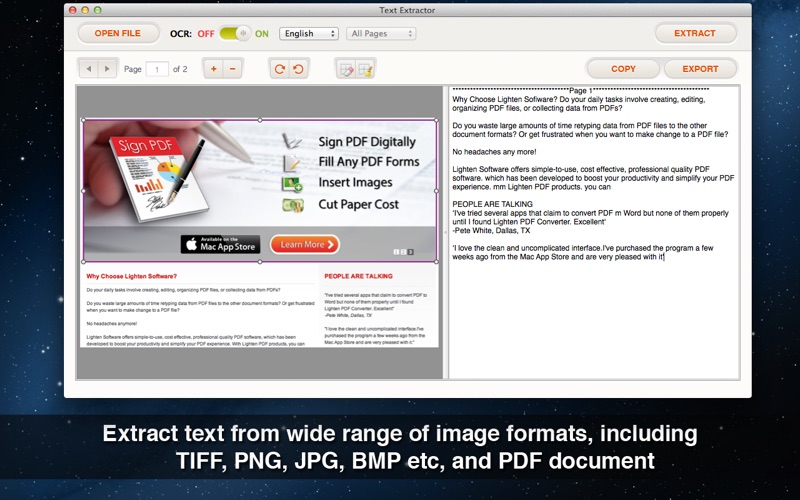
I had a 149 page pdf (that was rather clean) that I needed to convert. I did a little a research and I seen prices from free to $159 for software. I tried multiple free websites that offer the service but none did the job. So I started browsing the apps… This one caught my attention because of price so I figured why not give it a try. Based on the reviews and the free websites I already tried, I wasn’t too confident that it would work. Five minutes after the purchase, I had a the entire PDF converted and the text was 99.99% accurate if not more. I have to make little edits here and there but they are underlined and sure beats typing 149 pages. This has multiple languages that you can select but I only used the English one so I can’t say for the other. No images were imported in the new doc which I didn’t expect but I did have tables in the doc and it extracted the figures. All in all I could not be happier with the purchase.
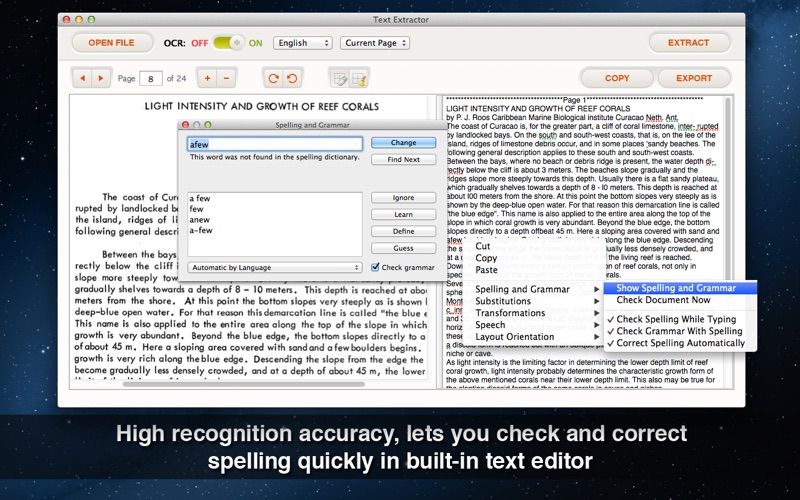
I have high quality pictures of text, yet, this application still fails to convert it. it misses most of the time at least 50% of the content is symbols and numbers. Some other times it might get the text correct but i does not get it complete. it extracts only half of a full page letter. the most desapointing part is that i paid $9.99. if it was only $1.99 i wouldt mind. that’s just too much for nothing. it lacks tools to extract specific text, its very plain.
The product is slow. Slow would be okay if it were more accurate. It claims to be 90+% accurate. It wasn’t for the PDFs I tried. And finally, most people don’t just scan a PDF and the OCR with the expectation of extracting a few works here or there. They would like the PDF to be searchable. This functionality is either missing or too hard to find. Either way, it should support saving searchable PDFs.

|

|

|

|

|

|

|

|

|

|
